
We have spent the last year solving the during problem in AI-assisted development.
How do we work alongside AI without losing architectural coherence? How do we structure teams so that the speed of AI generation does not outrun human judgment? How do we ensure that the conceptual identity of a system — the thing only humans can define — survives contact with an LLM that has never read the architecture decision records?
These are good questions. And we have made progress on them.
But there is a quieter problem that sits at the end of the workflow, one that we have been slower to name clearly: What happens in the last mile — between finished code and the repository?
The Confidence Gap
In principle, the answer seems obvious. You add a gate. AI reviews the diff before merge. If something looks wrong, it says so.
We tried this. The AI caught real things. In one case, it flagged a change to a shared interface and recommended involving someone with broader architectural context before proceeding. The recommendation was correct. The reasoning was sound.
And then the developer merged anyway.
Not out of malice. Not out of carelessness. But because the recommendation was advisory. It had no teeth. It was, in the end, a very articulate suggestion — and suggestions can be ignored.
This is the confidence gap: the distance between knowing something might be wrong and having a reason not to proceed.
Two Different Problems
The failure above is not a failure of AI quality. The AI was right. The failure is a category error — we used an awareness tool to try to solve a governance problem.
These are genuinely different things, and conflating them leads to architectures that feel complete but aren’t.
Awareness tools give developers better information before they act. A good AI review, a linting rule, a complexity warning — these work by changing what someone knows. Their effectiveness depends entirely on whether the person cares to act on what they now know. For most developers, most of the time, this is enough. The vast majority of code changes are local, low-stakes, and well within the competence of whoever is making them.
Governance tools make certain paths require certain steps. Branch protection rules. Required reviewers. CODEOWNERS. These work by changing what someone can do. They are not smarter than awareness tools. They are just non-optional.
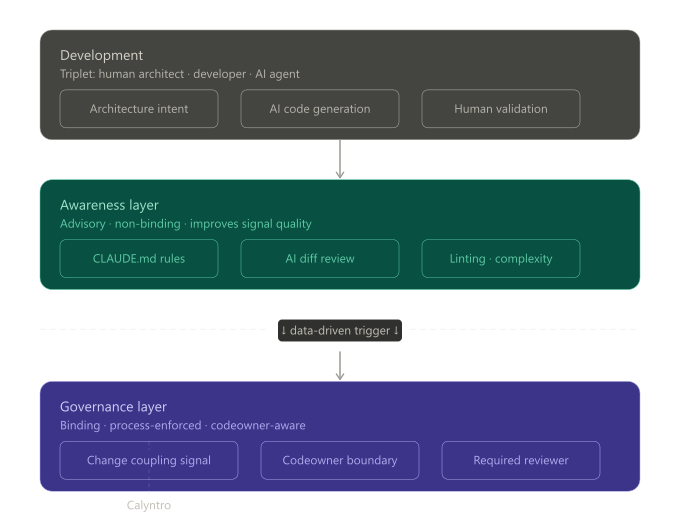
Awareness and Governance are distinct layers — conflating them leads to gaps.
The mistake is reaching for an awareness tool when you actually need governance — and then being surprised when awareness, unmoored from consequence, goes unheeded.
The Problem with Static Rules
Once you accept that some changes need genuine gates, the next question is which ones.
The obvious answer — interface changes always require an architectural review — is too blunt. Not every interface change is equally consequential. A small adjustment to an internal utility method is not the same as modifying a contract that three other modules depend on. Treating them identically produces process overhead that developers learn to route around, which is worse than no process at all.
What actually matters is not the type of change, but who it affects.
A change that touches only code you own is a different thing from a change that touches the boundary between your code and someone else’s. The first is a local decision. The second is a coordination problem — and coordination problems, left uncoordinated, are where systems quietly accumulate incoherence.
What Git History Already Knows
Here is the thing about coordination problems: they leave traces.
When two components are genuinely coupled — when changing one reliably requires changing the other — that pattern shows up in the commit history. It shows up as change coupling: files that have been modified together, repeatedly, across time.
This is not a prediction. It is a record. The history of the repository already contains a map of which changes have required coordination in the past. That map is not perfect — coupling patterns evolve — but it is far more precise than any static rule based on file type or directory structure.
If a proposed change touches files that have historically co-changed with files owned by a different team or individual, that is a signal worth taking seriously. Not because something is definitely wrong, but because the repository itself has told you that changes in this area have not historically been local decisions.
That is the difference between an advisory generated from a prompt and a trigger generated from data. One is an opinion. The other is evidence.
This is exactly what Calyntro surfaces through its change coupling analysis — not a rule someone wrote, but a pattern the repository itself produced.
Closing the Loop
What emerges from this is not a single solution but a layered one — and the layers need to be kept distinct.
AI review belongs in the awareness layer. It is genuinely useful there. It catches things that would otherwise require human eyes on every diff. It surfaces anomalies, flags deviations from stated patterns, asks questions a junior developer might not think to ask. Used well, it makes the average quality of code that reaches the gate meaningfully higher.
But the gate itself needs to be grounded in something more durable: the actual coupling structure of the codebase, derived from its history, mapped to its ownership. When a change crosses an ownership boundary that the repository’s own history suggests is real, that is when a governance step is warranted — not as a suggestion, but as a requirement.
The last mile is not a place for better prompts. It is a place for better data.
This post is part of an ongoing series on AI-assisted development and software architecture. Earlier posts in the series explore why coherence cannot be refactored into chaos, and why we structure development in threes.
Live Demo
Curious what this looks like in practice?
The full analysis runs live against the MongoDB open-source repository — no login, no setup required.