Ein Team plant eine größere Umstrukturierung. Drei Module sollen einem neuen Team übergeben werden, zwei weitere zusammengeführt. Der Engineering Manager ist zuversichtlich — die Architektur ist klar dokumentiert, die Übergabe sollte in zwei Sprints erledigt sein.
Vier Monate später ist das Projekt noch nicht abgeschlossen. Was niemand vorher gesehen hatte: Eines der übergebenen Module hatte in den letzten 18 Monaten exklusiv einen einzigen Entwickler als Ansprechpartner — der inzwischen das Unternehmen verlassen hatte. Ein anderes Modulpaar änderte sich faktisch immer gemeinsam, obwohl im Architekturdiagramm keine Verbindung eingezeichnet war. Und ein dritter Bereich zeigte seit Monaten stetig steigende Komplexität — unbemerkt, weil niemand den Trend über Sprints hinweg verfolgt hatte.
All das stand in der Git-Historie. Vollständig, datiert, nachvollziehbar. Niemand hatte systematisch hineingeschaut.
In jeder ernsthaften Codebase tauchen dieselben fünf Risikosignale auf. Und fast immer bleiben sie unentdeckt — nicht weil die Daten fehlen, sondern weil niemand sie liest.
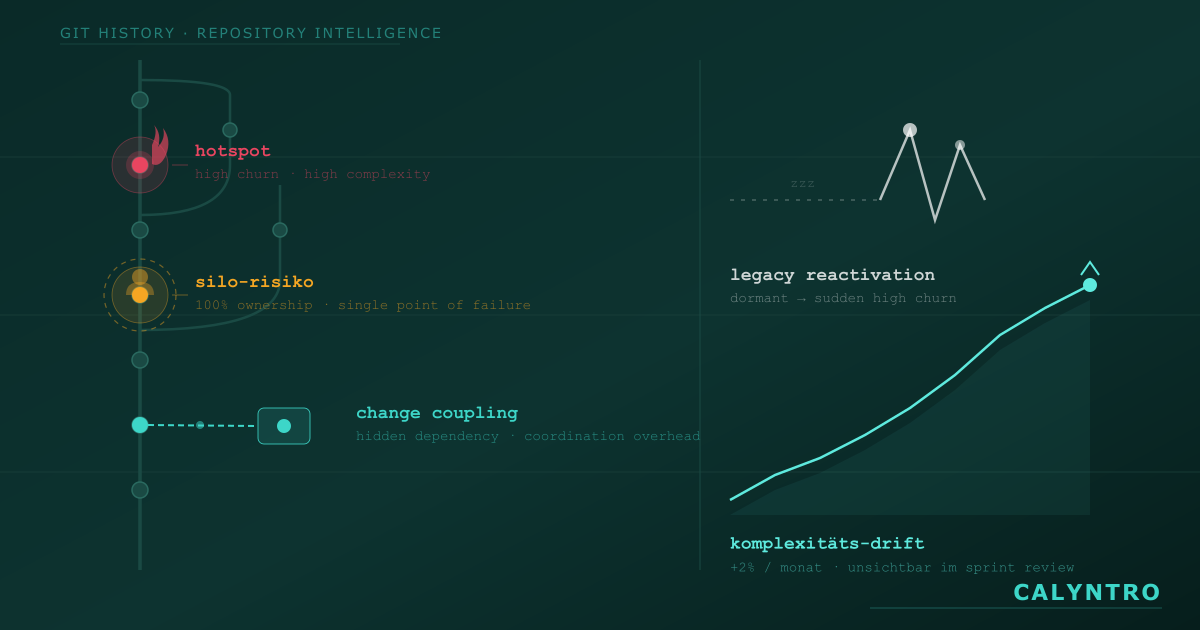
1. Hotspots: Dateien mit hoher Komplexität und hohem Churn
Einige Dateien tauchen in jedem zweiten Commit auf. Das ist kein Zeichen von Aktivität, sondern ein Warnsignal. Kritisch wird es, wenn hohe Komplexität und hoher Churn zusammenfallen. Dann ist das schwierigste Stück Code gleichzeitig das am häufigsten veränderte — jede Änderung trägt ein überdurchschnittliches Fehlerrisiko.
Hotspots absorbieren Entwicklungszeit, die nirgendwo sichtbar wird. Das Team schreibt keine Features, sondern kämpft gegen technische Schulden in einem einzigen File. In einem Open-Source-Projekt mit 43 Modulen fanden sich in 17 Modulen messbare Qualitätsrisiken — konzentriert auf wenige Hotspot-Dateien. Das ist keine Randerscheinung. Das ist strukturelle Verschwendung.
2. Silo-Risiko: Wenn eine Person das gesamte Wissen hält
Ein Entwickler verantwortet 80 % der Commit-Historie eines Moduls. Das wirkt wie Ownership — ist aber ein Single Point of Failure. Fällt diese Person aus, steht das Team vor einer Blackbox.
Bus-Factor-Risiko entsteht schleichend, nie durch bewusste Entscheidung. In einer Analyse fanden wir einen Entwickler mit exklusivem Wissen über 161 Dateien in einem einzigen Modul. Zwei Module hatten ein Silo-Risiko von 100 %: kein anderer Entwickler hatte je daran gearbeitet.
Für CTOs ist das kein Engineering-Problem — es ist ein operatives Risiko. Wenn diese Person geht, verliert das Unternehmen Wissen, das nirgendwo sonst existiert. Und dieses Risiko ist messbar, bevor es zum Problem wird.
3. Change Coupling: Versteckte Abhängigkeiten zwischen Modulen
Zwei Module haben architektonisch nichts miteinander zu tun — ändern sich aber über Monate hinweg gemeinsam, Commit für Commit. Dieses Muster nennt man Change Coupling, und es ist eines der am schwersten sichtbaren Risiken in Softwareprojekten.
Ursachen sind oft fehlende Abstraktionen — Logging, Konfiguration, ein Datenformat — die quer durch die Architektur ziehen, ohne sauber isoliert zu sein. Oder Teamgrenzen, die nicht zur tatsächlichen Modulstruktur passen: zwei Teams, die glauben, sie arbeiten unabhängig, die aber bei jeder Änderung aneinander reiben.
Das Entscheidende: Change Coupling ist im Code nicht sichtbar. Kein Linter, kein Code Review, keine statische Analyse erkennt es. Es ist nur auf der Ebene der Commit-Geschichte erkennbar. Für einen Engineering Manager ist das eine direkte Aussage über Koordinationskosten — und über Architekturentscheidungen, die längst überfällig sind.
4. Komplexitäts-Drift: Der schleichende Anstieg
Komplexität steigt selten sprunghaft. Sie wächst in kleinen Schritten, die niemand bewusst entscheidet — und die im Sprint Review einzeln betrachtet harmlos wirken. +2 % pro Monat ist unsichtbar. Nach 18 Monaten ist es eine andere Codebase.
Das eigentliche Problem ist der Zeitpunkt der Wahrnehmung: Wenn Komplexitäts-Drift offensichtlich wird, ist die Korrektur typischerweise fünfmal so teuer wie sechs Monate früher. Ein Snapshot hilft dabei nicht — entscheidend ist der Trend. Welche Module steigen konstant? Welche haben sich in einem halben Jahr verdoppelt?
Diese Frage ist nur mit Zeitreihendaten zu beantworten. Und sie ist nur dann rechtzeitig zu beantworten, wenn man nicht wartet, bis das Team fragt: „Wie ist das nur so geworden?"
5. Legacy Reactivation: Wenn alter Code plötzlich wieder heiß wird
Code, der zwei Jahre nicht angefasst wurde, zeigt plötzlich hohen Churn. Fast immer ein schlechtes Zeichen. Der ursprüngliche Autor ist möglicherweise nicht mehr im Team. Die Dokumentation beschreibt eine frühere Version. Die Annahmen, auf denen der Code basiert, gelten vielleicht nicht mehr.
Legacy Reactivation korreliert stark mit Bugs, die erst Wochen später sichtbar werden — weil der Fehler in einem Codepfad liegt, der selten durchlaufen wird. Für einen CTO bedeutet das eine bewusste Entscheidung: Entweder jetzt in Verständnis und Refactoring investieren, oder das Risiko explizit akzeptieren. Was nicht funktioniert: alten Code der plötzlich wieder lebt so zu behandeln wie frisch geschriebenen.
Diese Risiken stehen bereits in Ihrer Git-Historie
Diese fünf Signale benötigen keine neue Infrastruktur und kein monatelanges Audit. Sie stehen bereits in Ihrer Git-Historie — vollständig, datiert, nachvollziehbar. Die einzige Frage ist, ob jemand sie systematisch auswertet.
Calyntro macht genau das sichtbar: ohne Agents, ohne Cloud-Sync, ohne Zugriff auf Ihren Quellcode. Alles läuft in Ihrer eigenen Infrastruktur, die Daten verlassen sie nie.
Wenn Sie wissen möchten, welche dieser Signale Ihre Codebase heute zeigt — wir analysieren Ihre Git-Historie und zeigen Ihnen in einem 30-minütigen Call die konkreten Befunde. Kostenlos, ohne Setup-Aufwand, ohne Vorab-Verpflichtung.
Live Demo
Curious what this looks like in practice?
The full analysis runs live against the MongoDB open-source repository — no login, no setup required.